Semantic CSS With Intelligent Selectors

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 200,000+ folks.
 JavaScript Form Builder — Create JSON-driven forms without coding.
JavaScript Form Builder — Create JSON-driven forms without coding. Register For Free
Register For Free
 Devs love Storyblok - Learn why!
Devs love Storyblok - Learn why!
 Get a Free Trial
Get a Free Trial
“Form ever follows function. This is the law.” So said the architect and “father of skyscrapers” Louis Sullivan. For architects not wishing to crush hundreds of innocent people under the weight of a colossal building, this rule of thumb is pretty good. In design, you should always lead with function, and allow form to emerge as a result. If you were to lead with form, making your skyscraper look pretty would be easier, but at the cost of producing something pretty dangerous.
So much for architects. What about front-end architects — or “not real architects,” as we are sometimes known? Do we abide by this law or do we flout it?
With the advent of object-oriented CSS (OOCSS), it has become increasingly fashionable to “decouple presentation semantics from document semantics.” By leveraging the undesignated meanings of classes, it is possible to manage one’s document and the appearance of one’s document as curiously separate concerns.

In this article, we will explore an alternative approach to styling Web documents, one that marries document semantics to visual design wherever possible. With the use of “intelligent” selectors, we’ll cover how to query the extant, functional nature of semantic HTML in such a way as to reward well-formed markup. If you code it right, you’ll get the design you were hoping for.
If you are like me and have trouble doing or thinking about more than one thing at a time, I hope that employing some of these ideas will make your workflow simpler and more transferable between projects. In addition, the final section will cover a more reactive strategy: We’ll make a CSS bookmarklet that contains intelligent attribute selectors to test for bad HTML and report errors using pseudo-content.
Intelligent Selectors
With the invention of style sheets came the possibility of physically separating document code from the code used to make the document presentable. This didn’t help us to write better, more standards-aware HTML any more than the advent of the remote control resulted in better television programming. It just made things more convenient. By being able to style multiple elements with a single selector (p for paragraphs, for instance), consistency and maintenance became significantly less daunting prospects.
The p selector is an example of an intelligent selector in its simplest form. The p selector is intelligent because it has innate knowledge of semantic classification. Without intervention by the author, it already knows how to identify paragraphs and when to style them as such — simple yet effective, especially when you think of all of the automatically generated paragraphs produced by WYSIWYG editors.
So, if that’s an intelligent selector, what’s an unintelligent one? Any selector that requires the author to intervene and alter the document simply to elicit a stylistic nuance is an unintelligent selector. The class is a classic unintelligent selector because it is not naturally occurring as part of semantic convention. You can name and organize classes sensibly, but only with deliberation; they aren’t smart enough to take care of themselves, and browsers aren’t smart enough to take care of them for you.
Unintelligent selectors are time-intensive because they require styling hooks to be duplicated case by case. If we didn’t have p tags, we’d have to use unintelligent selectors to manufacture paragraphs, perhaps using .paragraph in each case. One of the downsides of this is that the CSS isn’t portable — that is, you can’t apply it to an HTML document without first going through the document and adding the classes everywhere they are required.
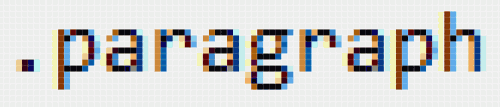
Unintelligent selectors at times seem necessary, or at least easier, and few of us are willing to rely entirely on intelligent selectors. However, some unintelligent selectors can become “plain stupid” selectors by creating a mismatch between document structure and presentation. I’ll be talking about the alarming frequency with which the unintelligent .button selector quickly becomes plain stupid.
Vive La Différence
Intelligent selectors are not confined just to the basic elements offered to us in HTML’s specification. To build complex intelligent selectors, you can defer to combinations of context and functional attribution to differentiate basic elements. Some elements, such as <a>, have a multitude of functional differences to consider and exploit. Other elements, such as <p>, rarely differ in explicit function but assume slightly different roles according to context.
header p {
/* styles for prologic paragraphs */
}
footer p {
/* styles for epilogic paragraphs */
}
Simple descendent selectors like these are extremely powerful because they enable us to visually disclose different types of the same element without having to physically alter the underlying document. This is the whole reason why style sheets were invented: to facilitate physical separation without breaking the conceptual reciprocity that should exist between document and design.
Inevitably, some adherents of OOCSS treat the descendent selector with some suspicion, with the more zealous insisting on markup such as the example below, found in BEM’s “Definitions” documentation.
<ul class="menu">
<li class="menu__item">…</li>
<li class="menu__item">…</li>
</ul>
I won’t cover contextual selectors any further because, unless you have a predilection for the kind of overprescription outlined above, I’m sure you already use them every day. Instead, we’ll concentrate on differentiation by function, as described in attributes and by attribute selectors.
Hyperlink Attributes
Even those who advocate for conceptual separation between CSS and HTML are happy to concede that some attributes — most attributes besides classes and custom data attributes, in fact — have an important bearing on the internal functioning of the document. Without href, your link won’t link to anything. Without type, the browser won’t know what sort of input to render. Without title, your abbr could be referring to either the British National Party or Banco Nacional de Panama.
Some of these attributes may improve the semantic detail of your document, while others are needed to ensure the correct rendering and functioning of their subject elements. If they’re not there, they should be, and if they are there, why not make use of them? You can’t write CSS without writing HTML.
The rel Attribute
The rel attribute emerged as a standard for link relations, a method of describing some specific purpose of a link. Not all links, you see, are functionally alike. Thanks to WordPress’ championing, rel=“prev” and rel=“next” are two of the most widely adopted values, helping to describe the relationship between individual pages of paginated blog content. Semantically, an a tag with a rel attribute is still an a tag, but we are able to be more specific. Unlike with classes, this specificity is semantically consequential.
The rel attribute should be used where appropriate because it is vindicated by HTML’s functional specification and can therefore be adopted by various user agents to enhance the experience of users and the accuracy of search engines. How, then, do you go about styling such links? With simple attribute selectors, of course:
[rel="prev"] {
/* styling for "previous links" */
}
[rel="next"] {
/* styling for "next" links */
}
Attribute selectors like these are supported by all but the most archaic, clockwork browsers, so that’s no reason not to use them anywhere the attributes exist. In terms of specificity, they have the same weight as classes. No woe there either, then. However, I recall it being suggested that we should decouple document and presentation semantics. I don’t want to lose the rel attributes (Google has implemented them, for one thing), so I’d better put an attribute that means nothing on there as well and style the element via that.
<a href="/previous-article-snippet/" rel="prev" class="prev">previous page</a>
The first thing to note here is that the only part of the element above that does not contribute to the document’s semantics is the class. The class, in other words, is the only thing in the document that has nothing functionally to do with it. In practice, this means that the class is the only thing that breaks with the very law of separation that it was employed to honor: It has a physical presence in the document without contributing to the document’s structure.
OK, so much for abstraction, but what about maintenance? Accepting that we’ve used the class as our styling hook, let’s now examine what happens when some editing or refactoring has led us to remove some attributes. Suppose we’ve used some pseudo-content to place a left-pointing arrow before the [rel=“prev”] link’s text:
.prev:before {
content: '2190'; /* encoding for a left-pointing arrow ("←") */
}

Removing the class will remove the pseudo-content, which in turn will remove the arrow (obviously). But without the arrow, nothing remains to elucidate the link’s extant prev relationship. By the same token, removing the rel attribute will leave the arrow intact: The class will continue to manage presentation, all the time disguising the nonexistence of a stated relationship in the document. Only by applying the style directly, via the semantic attribute that elicits it, can you keep your code and yourself honest and accurate. Only if it’s really there, as a function of the document, should you see it.
Attribute Substrings
I can imagine what you’re thinking: “That’s cute, but how many instances are there really for semantic styling hooks like these on hyperlinks? I’m going to have to rely on classes at some point.” I dispute that. Consider this incomplete list of functionally disimilar hyperlinks, all using the a element as their base:
- links to external resources,
- links to secure pages,
- links to author pages,
- links to help pages,
- links to previous pages (see example above),
- links to next pages (see example above again),
- links to PDF resources,
- links to documents,
- links to ZIP folders,
- links to executables,
- links to internal page fragments,
- links that are really buttons (more on these later),
- links that are really buttons and are toggle-able,
- links that open mail clients,
- links that cue up telephone numbers on smartphones,
- links to the source view of pages,
- links that open new tabs and windows,
- links to JavaScript and JSON files,
- links to RSS feeds and XML files.
That’s a lot of functional diversity, all of which is understood by user agents of all sorts. Now consider that in order for all of these specific link types to function differently, they must have mutually differential attribution. That is, in order to function differently, they must be written differently; and if they’re written differently, they can be styled differently.
In preparing this article, I created a proof of concept, named Auticons. Auticons is an icon font and CSS set that styles links automatically. All of the selectors in the CSS file are attribute selectors that invoke styles on well-formed hyperlinks, without the intervention of classes.

In many cases, Auticons queries a subset of the href value in order to determine the function of the hyperlink. Styling elements according to the way their attribute values begin or end or according to what substring they contain throughout the value is possible. Below are some common examples.
The Secure Protocol
Every well-formed (i.e. absolute) URL begins with a URI scheme followed by a colon. The most common on the Web is http:, but mailto: (for SMTP) and tel: (which refers to telephone numbers) are also prevalent. If we know how the href value of the hyperlink is expected to begin, we can exploit this semantic convention as a styling hook. In the following example for secure pages, we use the ^= comparator, which means “begins with.”
a[href^="https:"] {
/* style properties exclusive to secure pages */
}

In Auticons, links to secure pages become adorned with a padlock icon according to a specific semantic pattern, identifiable within the href attribute. The advantages of this are as follows:
- Links to secure pages — and only secure pages — are able to resemble links to secure pages by way of the padlock icon.
- Links to secure pages that cease to be true links to secure pages will lose the
httpsprotocol and, with it, the resemblance. - New secure pages will adopt the padlock icon and resemble links to secure pages automatically.
This selector becomes truly intelligent when applied to dynamic content. Because secure links exist as secure links even in the abstract, the attribute selector can anticipate their invocation: As soon as an editor publishes some content that contains a secure link, the link resembles a secure one to the user. No knowledge of class names or complex HTML editing is required, so even simple Markdown will create the style:
[Link to secure page](https://payment.example.com/)
Note that using the [href^=“https:“] prefix is not infallible because not all HTTPS pages are truly secure. Nonetheless, it is only as fallible as the browser itself. Major browsers all render a padlock icon natively in the address bar when displaying HTTPS pages.

File Types
As promised, you can also style hyperlinks according to how their href value ends. In practice, this means you can use CSS to indicate what type of file the link refers to. Auticons supports .txt, .pdf, .doc, .exe and many others. Here is the .zip example, which determines what the href ends with, using $=:
[href$=".gz"]:before {
content: 'E004'; /* unicode for the zip folder icon */
}
Combinations
You know how you can get all object-oriented and use a selection of multiple classes on elements to build up styles? Well, you can do that automatically with attribute selectors, too. Let’s compare:
/* The CSS for the class approach */
.new-window-icon:after {
content: '[new window icon]';
}
.twitter-icon:before {
content: '[twitter icon]';
}
/* The CSS for the attribute selector approach */
[target="_blank"]:after {
content: '[new window icon]';
}
[href*="twitter.com/"]:before {
content: '[twitter icon]';
}
(Note the *= comparator, which means “contains.” If the value string contains the substring twitter.com/, then the style will be honored.)
<!-- The HTML for the class approach -->
<a href="https://twitter.com/heydonworks" class="new-window-icon twitter-icon">@heydonworks</a>
<!-- The HTML for the attribute selector approach -->
<a href="https://twitter.com/heydonworks" target="_blank">@heydonworks</a>

Any content editor charged with adding a link to a Twitter page now needs to know only two things: the URL (they probably know the Twitter account already) and how to open links in new tabs (obtainable from a quick Google search).
Inheritance
Some unfinished business: What if we have a link that does not match any of our special attribute selectors? What if a hyperlink is just a plain old hyperlink? The selector is an easy one to remember, and performance fanatics will be pleased to hear that it couldn’t be any terser without existing at all.
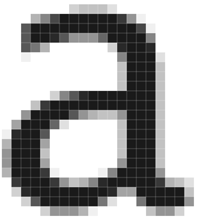
Flippancy aside, let me assure you that inheritance within the cascade works with attribute selectors just as it does with classes. First, style your basic a — perhaps with a text-decoration: underline rule to keep things accessible; then, progressively enhance further down the style sheet, using the attribute selectors at your disposal. Browsers such as Internet Explorer (IE) 7 do not support pseudo-content at all. Thanks to inheritance, at least the links will still look like links.
a {
color: blue;
text-decoration: underline;
}
a[rel="external"]:after {
content: '[icon for external links]';
}
Actual Buttons Are Actual
In the following section, we’ll detail the construction of our CSS bookmarklet for reporting code errors. Before doing this, let’s look at how plain stupid selectors can creep into our workflow in the first place.
Adherents of OOCSS are keen on classes because they can be reused, as components. Hence, .button is preferable to #button. I can think of one better component selector for button styles, though. Its name is easy to remember, too.
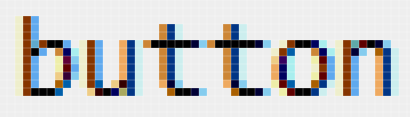
The `
Topcoat is an OOCSS BEM-based UI framework from Adobe. The CSS for Topcoat’s various button styles is more than 450 lines if you include the comment blocks. Each of these comment blocks suggests applying your button style in a manner similar to this introductory example:
<a class="topcoat-button">Button</a>
This example is not a button. No, sir. If it were a button, it would be marked up using <button>. In fact, in every single browser known to man, if it were marked up as a button and no author CSS was supplied, you could count on it looking like a button by default. It’s not, though; it’s marked up using <a>, which makes it a hyperlink — a hyperlink, in fact, that lacks an href, meaning it isn’t even a hyperlink. Technically, it’s just a placeholder for a hyperlink that you haven’t finished writing yet.

A dog in a shark costume does not a shark make. (Image: reader of the pack)
The examples in Topcoat’s CSS are only examples, but the premise that the class defines the element and not the HTML is deceptive. No amount of class name modification via “meaningful hyphenation” can make up for this invitation to turn your unintelligent selector into a plain stupid one and to just code stuff wrong.
Update: Since writing this article, Topcoat.io has replaced these examples with


