“Create Once, Publish Everywhere” With WordPress

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.

 Celebrating 10 million developers
Celebrating 10 million developers
 Register Free Now
Register Free Now Try ProtoPie AI free →
Try ProtoPie AI free →
 SurveyJS: White-Label Survey Solution for Your JS App
SurveyJS: White-Label Survey Solution for Your JS AppCOPE is a strategy for reducing the amount of work needed to publish our content into different mediums, such as website, email, apps, and others. First pioneered by NPR, it accomplishes its goal by establishing a single source of truth for content which can be used for all of the different mediums.
Having content that works everywhere is not a trivial task since each medium will have its own requirements. For instance, whereas HTML is valid for printing content for the web, this language is not valid for an iOS/Android app. Similarly, we can add classes to our HTML for the web, but these must be converted to styles for email.
The solution to this conundrum is to separate form from content: The presentation and the meaning of the content must be decoupled, and only the meaning is used as the single source of truth. The presentation can then be added in another layer (specific to the selected medium).
For example, given the following piece of HTML code, the <p> is an HTML tag which applies mostly for the web, and attribute class="align-center" is presentation (placing an element “on the center” makes sense for a screen-based medium, but not for an audio-based one such as Amazon Alexa):
<p class="align-center">Hello world!</p>
Hence, this piece of content cannot be used as a single source of truth, and it must be converted into a format which separates the meaning from the presentation, such as the following piece of JSON code:
{
content: "Hello world!",
placement: "center",
type: "paragraph"
}
This piece of code can be used as a single source of truth for content since from it we can recreate once again the HTML code to use for the web, and procure an appropriate format for other mediums.
Why WordPress
WordPress is ideal to implement the COPE strategy due of several reasons:
- It is versatile.
The WordPress database model does not define a fixed, rigid content model; on the contrary, it was created for versatility, enabling to create varied content models through the use of meta field, which allow the storing of additional pieces of data for four different entities: posts and custom post types, users, comments, and taxonomies (tags and categories). - It is powerful.
WordPress shines as a CMS (Content Management System), and its plugin ecosystem enables to easily add new functionalities. - It is widespread.
It is estimated that 1/3rd of websites run on WordPress. Then, a sizable amount of people working on the web know about and are able to use, i.e. WordPress. Not just developers but also bloggers, salesmen, marketing staff, and so on. Then, many different stakeholders, no matter their technical background, will be able to produce the content which acts as the single source of truth. - It is headless.
Headlessness is the ability to decouple the content from the presentation layer, and it is a fundamental feature for implementing COPE (as to be able to feed data to dissimilar mediums).
Since incorporating the WP REST API into core starting from version 4.7, and more markedly since the launch of Gutenberg in version 5.0 (for which plenty of REST API endpoints had to be implemented), WordPress can be considered a headless CMS, since most WordPress content can be accessed through a REST API by any application built on any stack.
In addition, the recently-created WPGraphQL integrates WordPress and GraphQL, enabling to feed content from WordPress into any application using this increasingly popular API. Finally, my own project PoP has recently added an implementation of an API for WordPress which allows to export the WordPress data as either REST, GraphQL or PoP native formats. - It has Gutenberg, a block-based editor that greatly aids the implementation of COPE because it is based on the concept of blocks (as explained in the sections below).
Blobs Versus Blocks To Represent Information
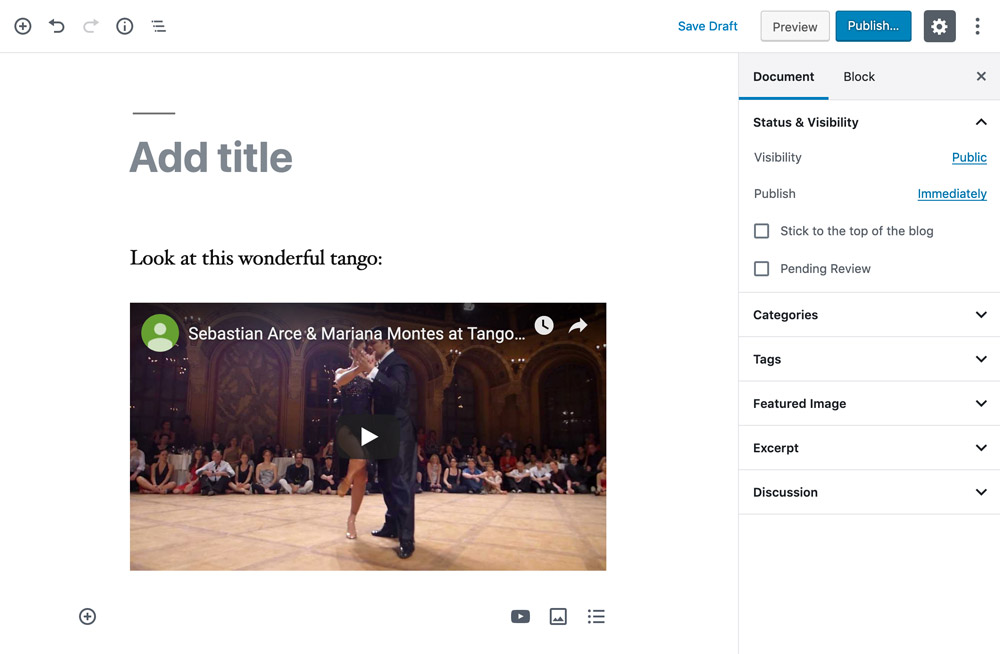
A blob is a single unit of information stored all together in the database. For instance, writing the blog post below on a CMS that relies on blobs to store information will store the blog post content on a single database entry — containing that same content:
<p>Look at this wonderful tango:</p>
<figure>
<iframe width="951" height="535" src="https://www.youtube.com/embed/sxm3Xyutc1s" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<figcaption>An exquisite tango performance</figcaption>
</figure>
As it can be appreciated, the important bits of information from this blog post (such as the content in the paragraph, and the URL, the dimensions and attributes of the Youtube video) are not easily accessible: If we want to retrieve any of them on their own, we need to parse the HTML code to extract them — which is far from an ideal solution.
Blocks act differently. By representing the information as a list of blocks, we can store the content in a more semantic and accessible way. Each block conveys its own content and its own properties which can depend on its type (e.g. is it perhaps a paragraph or a video?).
For example, the HTML code above could be represented as a list of blocks like this:
{
[
type: "paragraph",
content: "Look at this wonderful tango:"
],
[
type: "embed",
provider: "Youtube",
url: "https://www.youtube.com/embed/sxm3Xyutc1s",
width: 951,
height: 535,
frameborder: 0,
allowfullscreen: true,
allow: "accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture",
caption: "An exquisite tango performance"
]
}
Through this way of representing information, we can easily use any piece of data on its own, and adapt it for the specific medium where it must be displayed. For instance, if we want to extract all the videos from the blog post to show on a car entertainment system, we can simply iterate all blocks of information, select those with type="embed" and provider="Youtube", and extract the URL from them. Similarly, if we want to show the video on an Apple Watch, we need not care about the dimensions of the video, so we can ignore attributes width and height in a straightforward manner.
How Gutenberg Implements Blocks
Before WordPress version 5.0, WordPress used blobs to store post content in the database. Starting from version 5.0, WordPress ships with Gutenberg, a block-based editor, enabling the enhanced way to process content mentioned above, which represents a breakthrough towards the implementation of COPE. Unfortunately, Gutenberg has not been designed for this specific use case, and its representation of the information is different to the one just described for blocks, resulting in several inconveniences that we will need to deal with.
Let’s first have a glimpse on how the blog post described above is saved through Gutenberg:
<!-- wp:paragraph -->
<p>Look at this wonderful tango:</p>
<!-- /wp:paragraph -->
<!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} -->
<figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio">
<div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div>
<figcaption>An exquisite tango performance</figcaption>
</figure>
<!-- /wp:core-embed/youtube -->
From this piece of code, we can make the following observations:
Blocks Are Saved All Together In The Same Database Entry
There are two blocks in the code above:
<!-- wp:paragraph -->
<p>Look at this wonderful tango:</p>
<!-- /wp:paragraph -->
<!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} -->
<figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio">
<div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div>
<figcaption>An exquisite tango performance</figcaption>
</figure>
<!-- /wp:core-embed/youtube -->
With the exception of global (also called “reusable”) blocks, which have an entry of their own in the database and can be referenced directly through their IDs, all blocks are saved together in the blog post’s entry in table wp_posts.
Hence, to retrieve the information for a specific block, we will first need to parse the content and isolate all blocks from each other. Conveniently, WordPress provides function parse_blocks($content) to do just this. This function receives a string containing the blog post content (in HTML format), and returns a JSON object containing the data for all contained blocks.
Block Type And Attributes Are Conveyed Through HTML Comments
Each block is delimited with a starting tag <!-- wp:{block-type} {block-attributes-encoded-as-JSON} --> and an ending tag <!-- /wp:{block-type} --> which (being HTML comments) ensure that this information will not be visible when displaying it on a website. However, we can’t display the blog post directly on another medium, since the HTML comment may be visible, appearing as garbled content. This is not a big deal though, since after parsing the content through function parse_blocks($content), the HTML comments are removed and we can operate directly with the block data as a JSON object.
Blocks Contain HTML
The paragraph block has "<p>Look at this wonderful tango:</p>" as its content, instead of "Look at this wonderful tango:". Hence, it contains HTML code (tags <p> and </p>) which is not useful for other mediums, and as such must be removed, for instance through PHP function strip_tags($content).
When stripping tags, we can keep those HTML tags which explicitly convey semantic information, such as tags <strong> and <em> (instead of their counterparts <b> and <i> which apply only to a screen-based medium), and remove all other tags. This is because there is a great chance that semantic tags can be properly interpreted for other mediums too (e.g. Amazon Alexa can recognize tags <strong> and <em>, and change its voice and intonation accordingly when reading a piece of text). To do this, we invoke the strip_tags function with a 2nd parameter containing the allowed tags, and place it within a wrapping function for convenience:
function strip_html_tags($content)
{
return strip_tags($content, '<strong><em>');
}
The Video’s Caption Is Saved Within The HTML And Not As An Attribute
As can be seen in the Youtube video block, the caption "An exquisite tango performance" is stored inside the HTML code (enclosed by tag <figcaption />) but not inside the JSON-encoded attributes object. As a consequence, to extract the caption, we will need to parse the block content, for instance through a regular expression:
function extract_caption($content)
{
$matches = [];
preg_match('/<figcaption>(.*?)<\/figcaption>/', $content, $matches);
if ($caption = $matches[1]) {
return strip_html_tags($caption);
}
return null;
}
This is a hurdle we must overcome in order to extract all metadata from a Gutenberg block. This happens on several blocks; since not all pieces of metadata are saved as attributes, we must then first identify which are these pieces of metadata, and then parse the HTML content to extract them on a block-by-block and piece-by-piece basis.
Concerning COPE, this represents a wasted chance to have a really optimal solution. It could be argued that the alternative option is not ideal either, since it would duplicate information, storing it both within the HTML and as an attribute, which violates the DRY (Don’t Repeat Yourself) principle. However, this violation does already take place: For instance, attribute className contains value "wp-embed-aspect-16-9 wp-has-aspect-ratio", which is printed inside the content too, under HTML attribute class.
Implementing COPE
Note: I have released this functionality, including all the code described below, as WordPress plugin Block Metadata. You’re welcome to install it and play with it so you can get a taste of the power of COPE. The source code is available in this GitHub repo.
Now that we know what the inner representation of a block looks like, let’s proceed to implement COPE through Gutenberg. The procedure will involve the following steps:
- Because function
parse_blocks($content)returns a JSON object with nested levels, we must first simplify this structure. - We iterate all blocks and, for each, identify their pieces of metadata and extract them, transforming them into a medium-agnostic format in the process. Which attributes are added to the response can vary depending on the block type.
- We finally make the data available through an API (REST/GraphQL/PoP).
Let’s implement these steps one by one.
1. Simplifying The Structure Of The JSON Object
The returned JSON object from function parse_blocks($content) has a nested architecture, in which the data for normal blocks appear at the first level, but the data for a referenced reusable block are missing (only data for the referencing block are added), and the data for nested blocks (which are added within other blocks) and for grouped blocks (where several blocks can be grouped together) appear under 1 or more sublevels. This architecture makes it difficult to process the block data from all blocks in the post content, since on one side some data are missing, and on the other we don’t know a priori under how many levels data are located. In addition, there is a block divider placed every pair of blocks, containing no content, which can be safely ignored.
For instance, the response obtained from a post containing a simple block, a global block, a nested block containing a simple block, and a group of simple blocks, in that order, is the following:
[
// Simple block
{
"blockName": "core/image",
"attrs": {
"id": 70,
"sizeSlug": "large"
},
"innerBlocks": [],
"innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n",
"innerContent": [
"\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n"
]
},
// Empty block divider
{
"blockName": null,
"attrs": [],
"innerBlocks": [],
"innerHTML": "\n\n",
"innerContent": [
"\n\n"
]
},
// Reference to reusable block
{
"blockName": "core/block",
"attrs": {
"ref": 218
},
"innerBlocks": [],
"innerHTML": "",
"innerContent": []
},
// Empty block divider
{
"blockName": null,
"attrs": [],
"innerBlocks": [],
"innerHTML": "\n\n",
"innerContent": [
"\n\n"
]
},
// Nested block
{
"blockName": "core/columns",
"attrs": [],
// Contained nested blocks
"innerBlocks": [
{
"blockName": "core/column",
"attrs": [],
// Contained nested blocks
"innerBlocks": [
{
"blockName": "core/image",
"attrs": {
"id": 69,
"sizeSlug": "large"
},
"innerBlocks": [],
"innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n",
"innerContent": [
"\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n"
]
}
],
"innerHTML": "\n<div class=\"wp-block-column\"></div>\n",
"innerContent": [
"\n<div class=\"wp-block-column\">",
null,
"</div>\n"
]
},
{
"blockName": "core/column",
"attrs": [],
// Contained nested blocks
"innerBlocks": [
{
"blockName": "core/paragraph",
"attrs": [],
"innerBlocks": [],
"innerHTML": "\n<p>This is how I wake up every morning</p>\n",
"innerContent": [
"\n<p>This is how I wake up every morning</p>\n"
]
}
],
"innerHTML": "\n<div class=\"wp-block-column\"></div>\n",
"innerContent": [
"\n<div class=\"wp-block-column\">",
null,
"</div>\n"
]
}
],
"innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n",
"innerContent": [
"\n<div class=\"wp-block-columns\">",
null,
"\n\n",
null,
"</div>\n"
]
},
// Empty block divider
{
"blockName": null,
"attrs": [],
"innerBlocks": [],
"innerHTML": "\n\n",
"innerContent": [
"\n\n"
]
},
// Block group
{
"blockName": "core/group",
"attrs": [],
// Contained grouped blocks
"innerBlocks": [
{
"blockName": "core/image",
"attrs": {
"id": 71,
"sizeSlug": "large"
},
"innerBlocks": [],
"innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n",
"innerContent": [
"\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n"
]
},
{
"blockName": "core/paragraph",
"attrs": [],
"innerBlocks": [],
"innerHTML": "\n<p>Second element of the group</p>\n",
"innerContent": [
"\n<p>Second element of the group</p>\n"
]
}
],
"innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n",
"innerContent": [
"\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">",
null,
"\n\n",
null,
"</div></div>\n"
]
}
]
A better solution is to have all data at the first level, so the logic to iterate through all block data is greatly simplified. Hence, we must fetch the data for these reusable/nested/grouped blocks, and have it added on the first level too. As it can be seen in the JSON code above:
- The empty divider block has attribute
"blockName"with valueNULL - The reference to a reusable block is defined through
$block["attrs"]["ref"] - Nested and group blocks define their contained blocks under
$block["innerBlocks"]
Hence, the following PHP code removes the empty divider blocks, identifies the reusable/nested/grouped blocks and adds their data to the first level, and removes all data from all sublevels:
/**
* Export all (Gutenberg) blocks' data from a WordPress post
*/
function get_block_data($content, $remove_divider_block = true)
{
// Parse the blocks, and convert them into a single-level array
$ret = [];
$blocks = parse_blocks($content);
recursively_add_blocks($ret, $blocks);
// Maybe remove blocks without name
if ($remove_divider_block) {
$ret = remove_blocks_without_name($ret);
}
// Remove 'innerBlocks' property if it exists (since that code was copied to the first level, it is currently duplicated)
foreach ($ret as &$block) {
unset($block['innerBlocks']);
}
return $ret;
}
/**
* Remove the blocks without name, such as the empty block divider
*/
function remove_blocks_without_name($blocks)
{
return array_values(array_filter(
$blocks,
function($block) {
return $block['blockName'];
}
));
}
/**
* Add block data (including global and nested blocks) into the first level of the array
*/
function recursively_add_blocks(&$ret, $blocks)
{
foreach ($blocks as $block) {
// Global block: add the referenced block instead of this one
if ($block['attrs']['ref']) {
$ret = array_merge(
$ret,
recursively_render_block_core_block($block['attrs'])
);
}
// Normal block: add it directly
else {
$ret[] = $block;
}
// If it contains nested or grouped blocks, add them too
if ($block['innerBlocks']) {
recursively_add_blocks($ret, $block['innerBlocks']);
}
}
}
/**
* Function based on `render_block_core_block`
*/
function recursively_render_block_core_block($attributes)
{
if (empty($attributes['ref'])) {
return [];
}
$reusable_block = get_post($attributes['ref']);
if (!$reusable_block || 'wp_block' !== $reusable_block->post_type) {
return [];
}
if ('publish' !== $reusable_block->post_status || ! empty($reusable_block->post_password)) {
return [];
}
return get_block_data($reusable_block->post_content);
}
Calling function get_block_data($content) passing the post content ($post->post_content) as parameter, we now obtain the following response:
[[
{
"blockName": "core/image",
"attrs": {
"id": 70,
"sizeSlug": "large"
},
"innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n",
"innerContent": [
"\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n"
]
},
{
"blockName": "core/paragraph",
"attrs": [],
"innerHTML": "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n",
"innerContent": [
"\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n"
]
},
{
"blockName": "core/columns",
"attrs": [],
"innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n",
"innerContent": [
"\n<div class=\"wp-block-columns\">",
null,
"\n\n",
null,
"</div>\n"
]
},
{
"blockName": "core/column",
"attrs": [],
"innerHTML": "\n<div class=\"wp-block-column\"></div>\n",
"innerContent": [
"\n<div class=\"wp-block-column\">",
null,
"</div>\n"
]
},
{
"blockName": "core/image",
"attrs": {
"id": 69,
"sizeSlug": "large"
},
"innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n",
"innerContent": [
"\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n"
]
},
{
"blockName": "core/column",
"attrs": [],
"innerHTML": "\n<div class=\"wp-block-column\"></div>\n",
"innerContent": [
"\n<div class=\"wp-block-column\">",
null,
"</div>\n"
]
},
{
"blockName": "core/paragraph",
"attrs": [],
"innerHTML": "\n<p>This is how I wake up every morning</p>\n",
"innerContent": [
"\n<p>This is how I wake up every morning</p>\n"
]
},
{
"blockName": "core/group",
"attrs": [],
"innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n",
"innerContent": [
"\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">",
null,
"\n\n",
null,
"</div></div>\n"
]
},
{
"blockName": "core/image",
"attrs": {
"id": 71,
"sizeSlug": "large"
},
"innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n",
"innerContent": [
"\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n"
]
},
{
"blockName": "core/paragraph",
"attrs": [],
"innerHTML": "\n<p>Second element of the group</p>\n",
"innerContent": [
"\n<p>Second element of the group</p>\n"
]
}
]
Even though not strictly necessary, it is very helpful to create a REST API endpoint to output the result of our new function get_block_data($content), which will allow us to easily understand what blocks are contained in a specific post, and how they are structured. The code below adds such endpoint under /wp-json/block-metadata/v1/data/{POST_ID}:
/**
* Define REST endpoint to visualize a post’s block data
*/
add_action('rest_api_init', function () {
register_rest_route('block-metadata/v1', 'data/(?P\d+)', [
'methods' => 'GET',
'callback' => 'get_post_blocks'
]);
});
function get_post_blocks($request)
{
$post = get_post($request['post_id']);
if (!$post) {
return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404));
}
$block_data = get_block_data($post->post_content);
$response = new WP_REST_Response($block_data);
$response->set_status(200);
return $response;
}
To see it in action, check out this link which exports the data for this post.
2. Extracting All Block Metadata Into A Medium-Agnostic Format
At this stage, we have block data containing HTML code which is not appropriate for COPE. Hence, we must strip the non-semantic HTML tags for each block as to convert it into a medium-agnostic format.
We can decide which are the attributes that must be extracted on a block type by block type basis (for instance, extract the text alignment property for "paragraph" blocks, the video URL property for the "youtube embed" block, and so on).
As we saw earlier on, not all attributes are actually saved as block attributes but within the block’s inner content, hence, for these situations, we will need to parse the HTML content using regular expressions in order to extract those pieces of metadata.
After inspecting all blocks shipped through WordPress core, I decided not to extract metadata for the following ones:
"core/columns""core/column""core/cover" | These apply only to screen-based mediums and (being nested blocks) are difficult to deal with. |
"core/html" | This one only makes sense for web. |
"core/table""core/button""core/media-text" | I had no clue how to represent their data on a medium-agnostic fashion or if it even makes sense. |
This leaves me with the following blocks, for which I’ll proceed to extract their metadata:
'core/paragraph''core/image''core-embed/youtube'(as a representative of all the'core-embed'blocks)'core/heading''core/gallery''core/list''core/audio''core/file''core/video''core/code''core/preformatted''core/quote'&'core/pullquote''core/verse'
To extract the metadata, we create function get_block_metadata($block_data) which receives an array with the block data for each block (i.e. the output from our previously-implemented function get_block_data) and, depending on the block type (provided under property "blockName"), decides what attributes are required and how to extract them:
/**
* Process all (Gutenberg) blocks' metadata into a medium-agnostic format from a WordPress post
*/
function get_block_metadata($block_data)
{
$ret = [];
foreach ($block_data as $block) {
$blockMeta = null;
switch ($block['blockName']) {
case ...:
$blockMeta = ...
break;
case ...:
$blockMeta = ...
break;
...
}
if ($blockMeta) {
$ret[] = [
'blockName' => $block['blockName'],
'meta' => $blockMeta,
];
}
}
return $ret;
}
Let’s proceed to extract the metadata for each block type, one by one:
“core/paragraph”
Simply remove the HTML tags from the content, and remove the trailing breaklines.
case 'core/paragraph':
$blockMeta = [
'content' => trim(strip_html_tags($block['innerHTML'])),
];
break;
‘core/image’
The block either has an ID referring to an uploaded media file or, if not, the image source must be extracted from under <img src="...">. Several attributes (caption, linkDestination, link, alignment) are optional.
case 'core/image':
$blockMeta = [];
// If inserting the image from the Media Manager, it has an ID
if ($block['attrs']['id'] && $img = wp_get_attachment_image_src($block['attrs']['id'], $block['attrs']['sizeSlug'])) {
$blockMeta['img'] = [
'src' => $img[0],
'width' => $img[1],
'height' => $img[2],
];
}
elseif ($src = extract_image_src($block['innerHTML'])) {
$blockMeta['src'] = $src;
}
if ($caption = extract_caption($block['innerHTML'])) {
$blockMeta['caption'] = $caption;
}
if ($linkDestination = $block['attrs']['linkDestination']) {
$blockMeta['linkDestination'] = $linkDestination;
if ($link = extract_link($block['innerHTML'])) {
$blockMeta['link'] = $link;
}
}
if ($align = $block['attrs']['align']) {
$blockMeta['align'] = $align;
}
break;
It makes sense to create functions extract_image_src, extract_caption and extract_link since their regular expressions will be used time and again for several blocks. Please notice that a caption in Gutenberg can contain links (<a href="...">), however, when calling strip_html_tags, these are removed from the caption.
Even though regrettable, I find this practice unavoidable, since we can’t guarantee a link to work in non-web platforms. Hence, even though the content is gaining universality since it can be used for different mediums, it is also losing specificity, so its quality is poorer compared to content that was created and customized for the particular platform.
function extract_caption($innerHTML)
{
$matches = [];
preg_match('/<figcaption>(.*?)<\/figcaption>/', $innerHTML, $matches);
if ($caption = $matches[1]) {
return strip_html_tags($caption);
}
return null;
}
function extract_link($innerHTML)
{
$matches = [];
preg_match('/<a href="(.*?)">(.*?)<\/a>>', $innerHTML, $matches);
if ($link = $matches[1]) {
return $link;
}
return null;
}
function extract_image_src($innerHTML)
{
$matches = [];
preg_match('/<img src="(.*?)"/', $innerHTML, $matches);
if ($src = $matches[1]) {
return $src;
}
return null;
}
‘core-embed/youtube’
Simply retrieve the video URL from the block attributes, and extract its caption from the HTML content, if it exists.
case 'core-embed/youtube':
$blockMeta = [
'url' => $block['attrs']['url'],
];
if ($caption = extract_caption($block['innerHTML'])) {
$blockMeta['caption'] = $caption;
}
break;
‘core/heading’
Both the header size (h1, h2, …, h6) and the heading text are not attributes, so these must be obtained from the HTML content. Please notice that, instead of returning the HTML tag for the header, the size attribute is simply an equivalent representation, which is more agnostic and makes better sense for non-web platforms.
case 'core/heading':
$matches = [];
preg_match('/<h[1-6])>(.*?)<\/h([1-6])>/', $block['innerHTML'], $matches);
$sizes = [
null,
'xxl',
'xl',
'l',
'm',
'sm',
'xs',
];
$blockMeta = [
'size' => $sizes[$matches[1]],
'heading' => $matches[2],
];
break;
‘core/gallery’
Unfortunately, for the image gallery I have been unable to extract the captions from each image, since these are not attributes, and extracting them through a simple regular expression can fail: If there is a caption for the first and third elements, but none for the second one, then I wouldn’t know which caption corresponds to which image (and I haven’t devoted the time to create a complex regex). Likewise, in the logic below I’m always retrieving the "full" image size, however, this doesn’t have to be the case, and I’m unaware of how the more appropriate size can be inferred.
case 'core/gallery':
$imgs = [];
foreach ($block['attrs']['ids'] as $img_id) {
$img = wp_get_attachment_image_src($img_id, 'full');
$imgs[] = [
'src' => $img[0],
'width' => $img[1],
'height' => $img[2],
];
}
$blockMeta = [
'imgs' => $imgs,
];
break;
‘core/list’
Simply transform the <li> elements into an array of items.
case 'core/list':
$matches = [];
preg_match_all('/<li>(.*?)<\/li>/', $block['innerHTML'], $matches);
if ($items = $matches[1]) {
$blockMeta = [
'items' => array_map('strip_html_tags', $items),
];
}
break;
‘core/audio’
Obtain the URL of the corresponding uploaded media file.
case 'core/audio':
$blockMeta = [
'src' => wp_get_attachment_url($block['attrs']['id']),
];
break;
‘core/file’
Whereas the URL of the file is an attribute, its text must be extracted from the inner content.
case 'core/file':
$href = $block['attrs']['href'];
$matches = [];
preg_match('/<a href="'.str_replace('/', '\/', $href).'">(.*?)<\/a>/', $block['innerHTML'], $matches);
$blockMeta = [
'href' => $href,
'text' => strip_html_tags($matches[1]),
];
break;
‘core/video’
Obtain the video URL and all properties to configure how the video is played through a regular expression. If Gutenberg ever changes the order in which these properties are printed in the code, then this regex will stop working, evidencing one of the problems of not adding metadata directly through the block attributes.
case 'core/video':
$matches = [];
preg_match('/‘core/code’
Simply extract the code from within <code />.
case 'core/code':
$matches = [];
preg_match('/<code>(.*?)<\/code>/is', $block['innerHTML'], $matches);
$blockMeta = [
'code' => $matches[1],
];
break;
‘core/preformatted’
Similar to <code />, but we must watch out that Gutenberg hardcodes a class too.
case 'core/preformatted':
$matches = [];
preg_match('/<pre class="wp-block-preformatted">(.*?)<\/pre>/is', $block['innerHTML'], $matches);
$blockMeta = [
'text' => strip_html_tags($matches[1]),
];
break;
‘core/quote’ And ‘core/pullquote’
We must convert all inner <p /> tags to their equivalent generic "\n" character.
case 'core/quote':
case 'core/pullquote':
$matches = [];
$regexes = [
'core/quote' => '/<blockquote class=\"wp-block-quote\">(.*?)<\/blockquote>/',
'core/pullquote' => '/<figure class=\"wp-block-pullquote\"><blockquote>(.*?)<\/blockquote><\/figure>/',
];
preg_match($regexes[$block['blockName']], $block['innerHTML'], $matches);
if ($quoteHTML = $matches[1]) {
preg_match_all('/<p>(.*?)<\/p>/', $quoteHTML, $matches);
$blockMeta = [
'quote' => strip_html_tags(implode('\n', $matches[1])),
];
preg_match('/<cite>(.*?)<\/cite>/', $quoteHTML, $matches);
if ($cite = $matches[1]) {
$blockMeta['cite'] = strip_html_tags($cite);
}
}
break;
‘core/verse’
Similar situation to <pre />.
case 'core/verse':
$matches = [];
preg_match('/<pre class="wp-block-verse">(.*?)<\/pre>/is', $block['innerHTML'], $matches);
$blockMeta = [
'text' => strip_html_tags($matches[1]),
];
break;
3. Exporting Data Through An API
Now that we have extracted all block metadata, we need to make it available to our different mediums, through an API. WordPress has access to the following APIs:
- REST, through the WP REST API (integrated in WordPress core)
- GraphQL, through WPGraphQL
- PoP, through its implementation for WordPress
Let’s see how to export the data through each of them.
REST
The following code creates endpoint /wp-json/block-metadata/v1/metadata/{POST_ID} which exports all block metadata for a specific post:
/**
* Define REST endpoints to export the blocks' metadata for a specific post
*/
add_action('rest_api_init', function () {
register_rest_route('block-metadata/v1', 'metadata/(?P\d+)', [
'methods' => 'GET',
'callback' => 'get_post_block_meta'
]);
});
function get_post_block_meta($request)
{
$post = get_post($request['post_id']);
if (!$post) {
return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404));
}
$block_data = get_block_data($post->post_content);
$block_metadata = get_block_metadata($block_data);
$response = new WP_REST_Response($block_metadata);
$response->set_status(200);
return $response;
}
To see it working, this link (corresponding to this blog post) displays the metadata for blocks of all the types analyzed earlier on.
GraphQL (Through WPGraphQL)
GraphQL works by setting-up schemas and types which define the structure of the content, from which arises this API’s power to fetch exactly the required data and nothing else. Setting-up schemas works very well when the structure of the object has a unique representation.
In our case, however, the metadata returned by a new field "block_metadata" (which calls our newly-created function get_block_metadata) depends on the specific block type, so the structure of the response can vary wildly; GraphQL provides a solution to this issue through a Union type, allowing to return one among a set of different types. However, its implementation for all different variations of the metadata structure has proved to be a lot of work, and I quit along the way 😢.
As an alternative (not ideal) solution, I decided to provide the response by simply encoding the JSON object through a new field "jsonencoded_block_metadata":
/**
* Define WPGraphQL field "jsonencoded_block_metadata"
*/
add_action('graphql_register_types', function() {
register_graphql_field(
'Post',
'jsonencoded_block_metadata',
[
'type' => 'String',
'description' => __('Post blocks encoded as JSON', 'wp-graphql'),
'resolve' => function($post) {
$post = get_post($post->ID);
$block_data = get_block_data($post->post_content);
$block_metadata = get_block_metadata($block_data);
return json_encode($block_metadata);
}
]
);
});
PoP
Note: This functionality is available on its own GitHub repo.
The final API is called PoP, which is a little-known project I’ve been working on for several years now. I have recently converted it into a full-fledged API, with the capacity to produce a response compatible with both REST and GraphQL, and which even benefits from the advantages from these 2 APIs, at the same time: no under/over-fetching of data, like in GraphQL, while being cacheable on the server-side and not susceptible to DoS attacks, like REST. It offers a mix between the two of them: REST-like endpoints with GraphQL-like queries.
The block metadata is made available through the API through the following code:
class PostFieldValueResolver extends AbstractDBDataFieldValueResolver
{
public static function getClassesToAttachTo(): array
{
return array(\PoP\Posts\FieldResolver::class);
}
public function resolveValue(FieldResolverInterface $fieldResolver, $resultItem, string $fieldName, array $fieldArgs = [])
{
$post = $resultItem;
switch ($fieldName) {
case 'block-metadata':
$block_data = \Leoloso\BlockMetadata\Data::get_block_data($post->post_content);
$block_metadata = \Leoloso\BlockMetadata\Metadata::get_block_metadata($block_data);
// Filter by blockName
if ($blockName = $fieldArgs['blockname']) {
$block_metadata = array_filter(
$block_metadata,
function($block) use($blockName) {
return $block['blockName'] == $blockName;
}
);
}
return $block_metadata;
}
return parent::resolveValue($fieldResolver, $resultItem, $fieldName, $fieldArgs);
}
}
To see it in action, this link displays the block metadata (+ ID, title and URL of the post, and the ID and name of its author, à la GraphQL) for a list of posts.
In addition, similar to GraphQL arguments, our query can be customized through field arguments, enabling to obtain only the data that makes sense for a specific platform. For instance, if we desire to extract all Youtube videos added to all posts, we can add modifier (blockname:core-embed/youtube) to field block-metadata in the endpoint URL, like in this link. Or if we want to extract all images from a specific post, we can add modifier (blockname:core/image) like in this other link|id|title).
Conclusion
The COPE (“Create Once, Publish Everywhere”) strategy helps us lower the amount of work needed to create several applications which must run on different mediums (web, email, apps, home assistants, virtual reality, etc) by creating a single source of truth for our content. Concerning WordPress, even though it has always shined as a Content Management System, implementing the COPE strategy has historically proved to be a challenge.
However, a couple of recent developments have made it increasingly feasible to implement this strategy for WordPress. On one side, since the integration into core of the WP REST API, and more markedly since the launch of Gutenberg, most WordPress content is accessible through APIs, making it a genuine headless system. On the other side, Gutenberg (which is the new default content editor) is block-based, making all metadata inside a blog post readily accessible to the APIs.
As a consequence, implementing COPE for WordPress is straightforward. In this article, we have seen how to do it, and all the relevant code has been made available through several repositories. Even though the solution is not optimal (since it involves plenty of parsing HTML code), it still works fairly well, with the consequence that the effort needed to release our applications to multiple platforms can be greatly reduced. Kudos to that!
Further Reading
- WordPress Playground: From 5-Minute Install To Instant Spin-Up
- The Modern Way To Create And Host A WordPress Site
- WordPress Full-Site Editing: A Deep Dive Into The New Feature
- Building Gatsby Themes For WordPress-Powered Websites


