Are Imposter Domains Re-Publishing Your Website?

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Register for Free
Register for Free

 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.
 Celebrating 10 million developers
Celebrating 10 million developers
We think of web scraping as a tool used to harvest web content for information analysis purposes, sometimes to the detriment of the site owner. For example, someone might web scrape all the product pages of a competitor’s retail site to harvest information about products being offered and current pricing to try to gain a competitive edge.
Web scraping can be used to harvest marketing data, such as identifying good keywords for advertising campaigns, identifying trending topics for blog posts, or identifying influencers in important blogs and news sites. Manufacturers might scrape retail sites to make sure that Manufacturer Advertised Pricing (MAP) is being adhered to, and security auditors might scrape sites to look for vulnerabilities or breaches in privacy policies. And of course, scrapers could scrape your site to look for security vulnerabilities or exposed contact or sales lead details. None of these activities would result in the scraped content being re-published or delivered to end-users.
There are situations, however, where the scraped web page content is delivered as a page itself directly to visitors. As we shall see below, this can be done for benign or not-so-benign reasons. In the worst-case scenarios, these can be true imposter domains, seeking to engage with real users without acknowledging the true source of your content. Even in benign use cases, however, you lose some control over the visitor’s experience. When your content is delivered by other means, from other servers or platforms, it can put the user experience and commercial relationship you have built up with your users at risk.
How can you identify, track, and manage this risk to your business? We explore how you can use web analytics or real user measurement data on your website to get insight into any imposter domains re-publishing your work. We also describe the most common types of content re-publishing we see in real-world data we collected in Akamai mPulse, both benign and problematic, so you know what to look for in your data.
How To Track Suspicious Activity
If you are just starting out wondering if someone might be re-publishing your web content, the easiest thing to do is a Google search. Copy a ten or twelve-word sentence from a page of interest on your site into the Google search bar, put it inside double-quotes, and click on Search. You should hopefully see your own site in the search results, but if you are finding that exact sentence matching on other sites, you may be the victim of re-publishing. This approach is obviously a bit ad-hoc. You could maybe script up some Google searches to run these kinds of checks periodically. But how many pages do you check? How can you reliably pick the content on the pages that the re-publishing is not going to modify? And what if the re-published page views never make it into Google’s search results?
A better approach is to use the data you are already collecting with your web analytics or Real User Measurement (RUM) services. These services vary considerably in their capabilities and the depth of data that is collected. They all generally are instrumented as JavaScript processes that are loaded onto your site’s web pages through a tag or snippet of loader code. When the service determines that a page view (and/or some other user activity of interest) is completed, it sends a “beacon” of data back to a collection system, where the data is then further processed, aggregated, and stored for future analysis.
To help identify the re-publishing of web pages by imposter domains, what you want is a service that:
- Collects data for every page view on the site (ideally);
- Collects the full URL of the base page HTML resource of the page view;
- Accepts beacons even if the hostname in that base page URL is not the one your site is published under;
- Allows you to query the collected data yourself and/or already has data queries designed to find “imposter domains”.
What Happens When A Web Page Is Re-Published?
When a web page is scraped with the intention of being delivered as a complete page view to an end-user, the scraper may modify the content. The modifications may be extensive. Modifying some content is easier than others, and while an imposter domain might change text or images, modifying JavaScript can be a more challenging proposition. Attempted modifications in JavaScript might break page functionality, inhibit proper rendering, or present other problems.
The good news for us is that web analytics trackers or real user measurement services are instrumented as JavaScript and many imposter domains are unlikely to try to modify the content to remove them because of the risks that it might break the page. If the scraper does not intentionally remove the loader snippet code or tag for your web analytics or RUM service, generally speaking, they will load successfully and generate a beacon for the page view — giving you evidence of the imposter domain activity.
This is the key to tracking imposter domains with web analytics or RUM data. Even if none of the page content is delivered from your platform or servers, so long as the JavaScript code you are using for analytics or performance tracking loads, you can still get data about the page view.
Turning The Data Into Information
Now that you have data, you can mine it for evidence of imposter domains. At the most basic, this is a database query that counts the number of page views by each hostname in the page URL, something like this pseudocode:
results = query("""
select
host,
count(*) as count
from
$(tableName)
where
timestamp between '$(startTime)' and '$(endTime)'
and url not like 'file:%'
group by 1
order by 2 desc
""");
Any hostname in the results that is not one your site uses is an imposter domain and worth investigating. For ongoing monitoring of the data, you will likely want to categorize the imposter domains you see in the data and have identified.
For example, some domains used by Natural Language Translation services that re-publish entire web pages might look like this:
# Translation domains
translationDomains = ["convertlanguage.com","dichtienghoa.com","dict.longdo.com",
"motionpoint.com","motionpoint.net","opentrad.com","papago.naver.net","rewordify.com",
"trans.hiragana.jp","translate.baiducontent.com","translate.goog",
"translate.googleusercontent.com","translate.sogoucdn.com","translate.weblio.jp",
"translatetheweb.com","translatoruser-int.com","transperfect.com","webtrans.yodao.com",
"webtranslate.tilde.com","worldlingo.com"]
Depending on your needs, you might build up arrays of “acceptable” and “problem” domains, or categorize the imposter domains by their function or type. Below are the most common types of imposter domains you might see in real-world data.
Benign Re-publishing
Not all scraped web pages delivered from a third-party domain are going to be malicious. Based on looking at Akamai mPulse data across a broad spectrum of customers, most page views from imposter domains are actually services that a site visitor is intentionally choosing to use. A site visitor may be able to enjoy page content that they would find inaccessible. In some cases, the services are likely being used by the employees of the site owner itself.
The major categories described here are by no means exhaustive.
Natural Language Translation
The most common imposter domains are those used by natural language translation services. These services can scrape a web page, translate the encoded text on the page into another language and deliver that modified content to the end-user.
The page that the end-user sees will have a URL from the top-level domain of the translation service (such as translate.goog, translatoruser-int.com, or translate.weblio.jp among many others). rewordify.com changes the English text on a page into simpler sentences for beginning English speakers. While you have no control over the quality of the translations or the performance of the delivered page experience, it is safe to assume that most site owners would not consider this to be a business risk or concern.
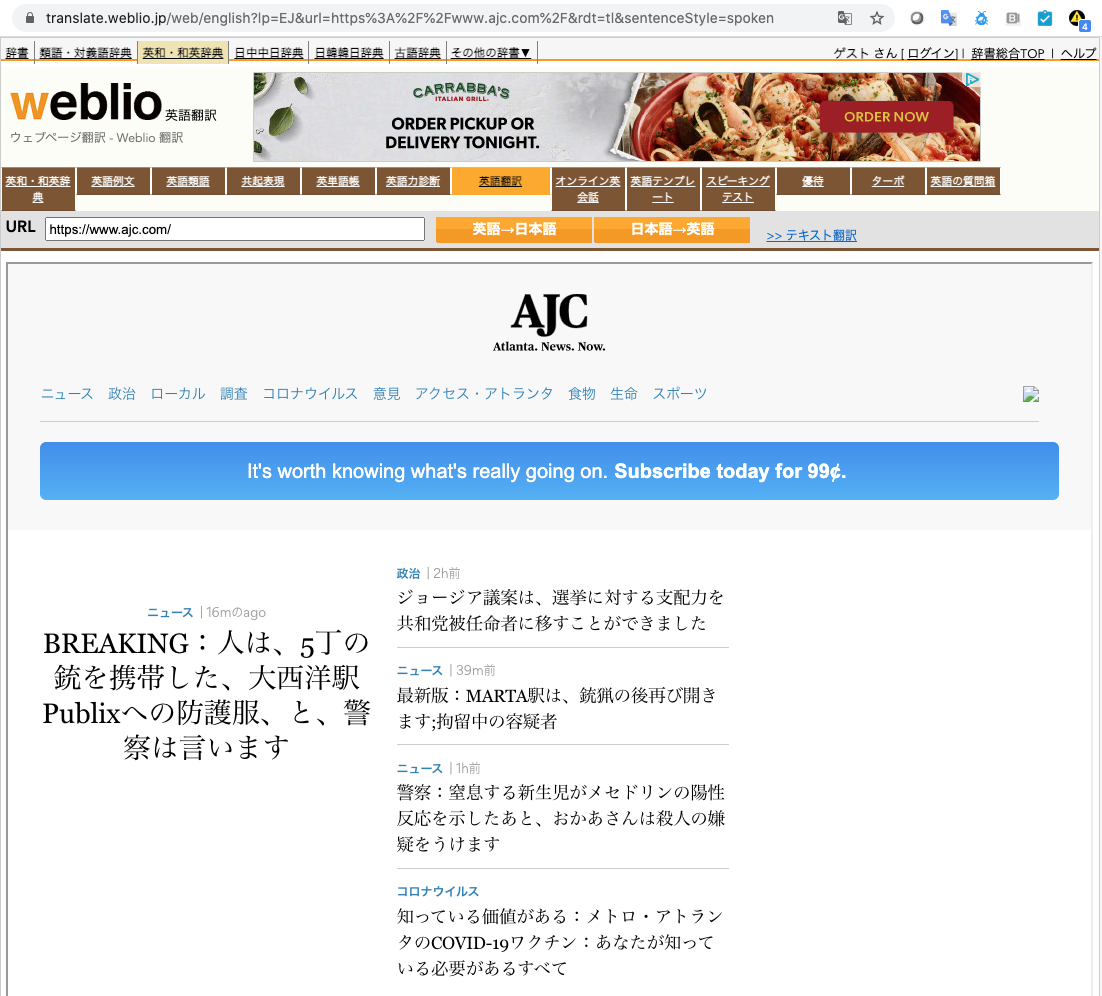
Search Engine And Web Archive Cached Results
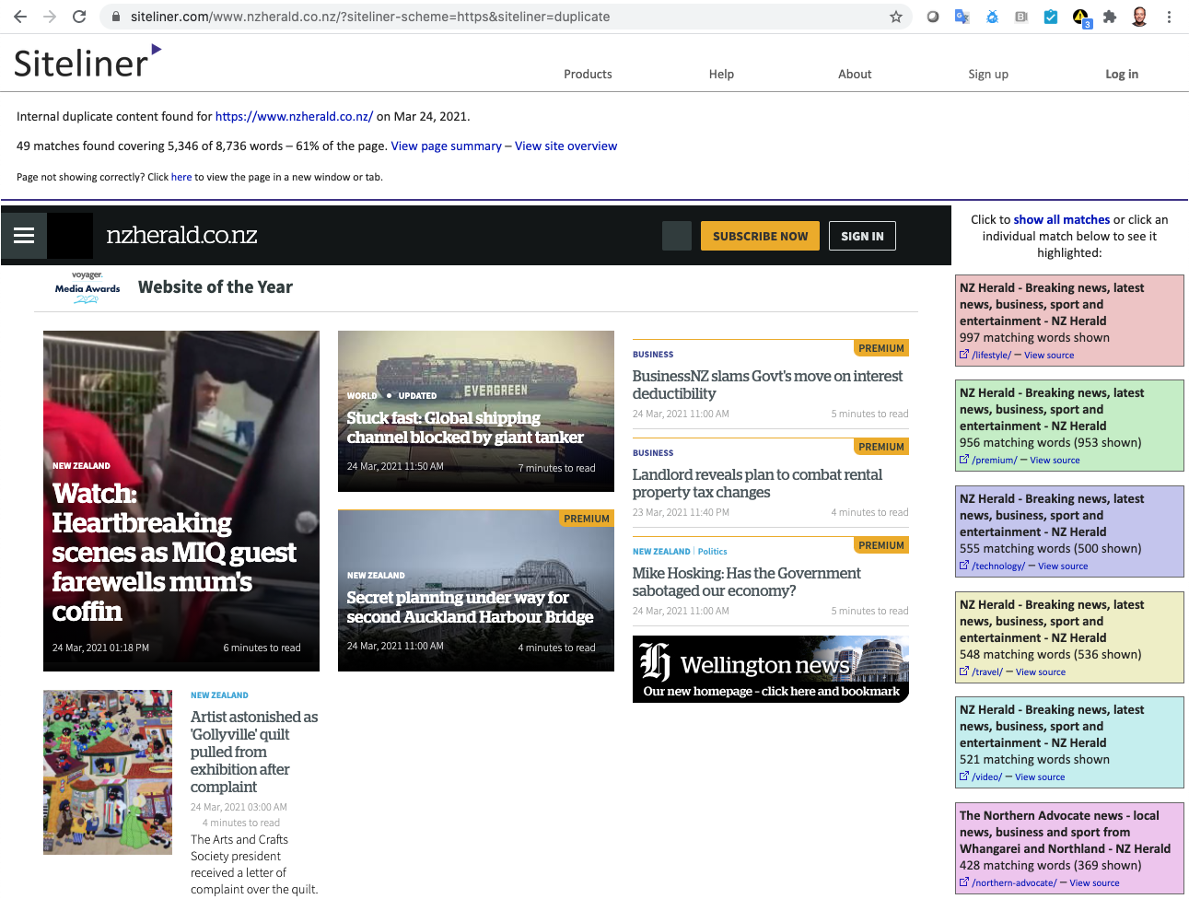
Another common category of imposter domains are domains used by search engines for delivering cached results or archived versions of page views. Typically, these would be pages that might no longer be available on the site but are available in third-party archives.
You might want to know about the frequency of these page views and deeper analysis could determine the specifics of what end-users were seeking in the online caches and archives. With the full URL for each request made to the online caches and archives, you should be able to identify keywords or topics that feature most often in those kinds of page views.

Developer Tools
These services will typically be used by your own employees as part of the natural business of developing and running your site. A typical developer tool might scrape an entire web page, analyze it for syntax errors in JavaScript, XML, HTML, or CSS, and display a marked-up version of the page for the developer to explore.
In addition to syntax errors, tools might also evaluate a site for compliance with accessibility or other legally required standards. Some example services seen in the real world include codebeautify.org, webaim.org, and jsonformatter.org.
Content Publishing Tools
Very similar to developer tools are tools that you might use to manage your content publishing needs. The most commonly seen example is the Google Ads Preview tool, which fetches a page, modifies it to include an ad tag and ad content from Google, and displays it to the site owner to see what the result would look like if published.
Another kind of content publishing tool is a service that fetches a web page, checks it against databases for any potential copyright violation or plagiarism, and displays the page with markup to identify any potentially offending content.
Transcoder Domains
Some services deliver a web page in altered form for either improved performance or improved display characteristics. The most common service of this type is Google Web Light. Available in a limited number of countries on Android OS devices with slow mobile network connections, Google Web Light transcodes the web page to deliver up to 80% fewer bytes while preserving a “majority of the relevant content” all in the name of delivering the content into the Android Mobile browser that much faster.
Other transcoder services modify the page content to change its presentation, e.g. printwhatyoulike.com removes advertising elements in preparation for printing to paper, and marker.to lets a user “mark up” a web page with a virtual yellow highlighter and share the page with others. While transcoder services can be well-intended, there is potential for both abuse (removing advertising) and potential questions of content integrity that you, as a site owner, need to be aware of.
Locally Saved Copies Of Web Pages
While not common, we do see beacons in the Akamai mPulse data with pages served from file:// URLs. These are page views loaded from a previously-viewed web page that was saved to device local storage. Because every device could have a different file system structure, resulting in an infinite number of “domains” in the URL data, it generally does not make sense to try to aggregate these for patterns. It is safe to assume that site owners would not consider this to be a business risk or concern.
Web Proxy Services
Another category of imposter domains that may be acceptable are those used by web proxy services. There are two large subcategories of presumed benign proxy services. One is institutional proxies, such as a university library system subscribing to an online news publication in order to grant access to its student body. When a student views the site, the page may be delivered from a host name in the university’s top-level domain.
It is safe to assume that most publishers would not consider this to be a business risk or concern if it is part of their business model. The other major type of benign proxies are sites that aim to offer anonymity so that visitors can consume a website content without being tracked or identified. The most common example of that latter subcategory is the anonymousbrowser.org service. The users of these services may or may not be well-intentioned.
Malicious Re-Publishing
While we have seen that there can be benign reasons for a web page to be scraped and then delivered from an alternative domain (and in fact, research shows that benign use cases are by far the most commonly seen in the Akamai mPulse real user measurement data), there are certainly instances where the intentions of the scrapers are malicious. Scraped content can be used to generate revenue in a variety of ways from simply passing off stolen content as one’s own to attempting to steal credentials or other secrets. Malicious use cases can harm both the site owner and/or the site visitor.
Ad Scraping
In the publishing industry, ad revenue is critical to the commercial success or failure of websites. Of course, selling ads requires content that visitors want to consume, and some bad actors may find it easier to steal that content than to create it themselves. Ad scrapers can harvest entire articles from a site and re-publish them on a different top-level domain with completely new advertising tags. If the scraper is not sophisticated enough to fully separate the content from the page structure, and for example includes core page JavaScript code including the loader snippet for your web analytics or RUM service, you can get beacons of data for these page views.
Phishing
Phishing is a fraudulent attempt to get users to reveal sensitive or private information such as access credentials, credit card numbers, social security numbers, or other data by impersonating a trusted site. To look as authentic as possible, phishing sites are often built by scraping the legitimate site that they aim to impersonate. Again, if the scraper is not sophisticated enough to fully separate the content from the page structure, and for example includes core page code including the loader snippet for your web analytics or RUM service, you can get beacons for these page views in mPulse.
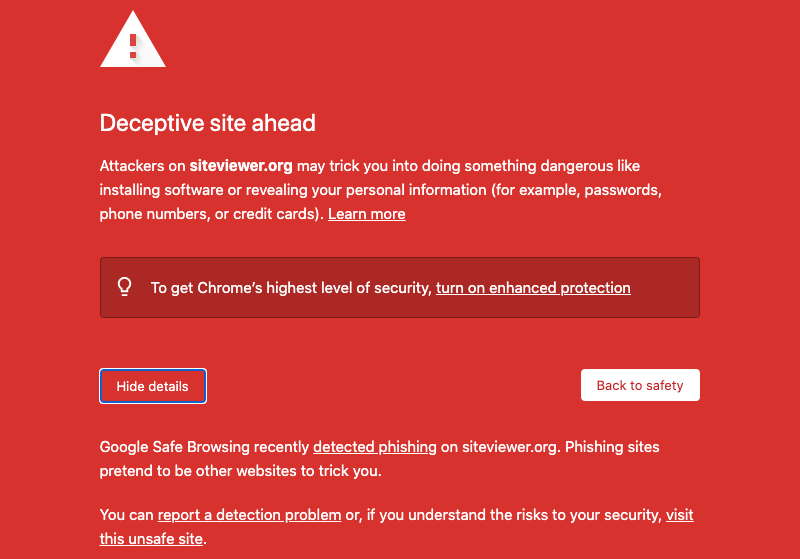
Browser Or Search Hijacking
A web page may be scraped and re-published with additional JavaScript that contains browser or search hijacking attack code. Unlike phishing, which tempts users to surrender valuable data, this kind of attack attempts to make changes to the browser settings. Simply changing the browser’s default search engine to point to one that the attacker gains affiliate search result revenue from could be profitable for a bad actor. If the scraper is not sophisticated, injecting new attack code but not changing the pre-existing core page code including the loader snippet for your web analytics or RUM service, you can get beacons for these page views in mPulse.
Paywall Or Subscription Bypass Proxies
Some services claim to help end-users access pages on sites that require subscriptions to view without having a valid login. For some content publishers, subscription fees can be a very significant portion of site revenue. For others, logins may be required to remain in legal compliance for users to consume content that is restricted by age, citizenship, residency, or other criteria.
Proxy services that bypass (or attempt to bypass) these access restrictions pose financial and legal risks to your business. Subjectively, many of these services appear to be focused specifically on pornography sites, but all website owners should be on the lookout for these bad actors.
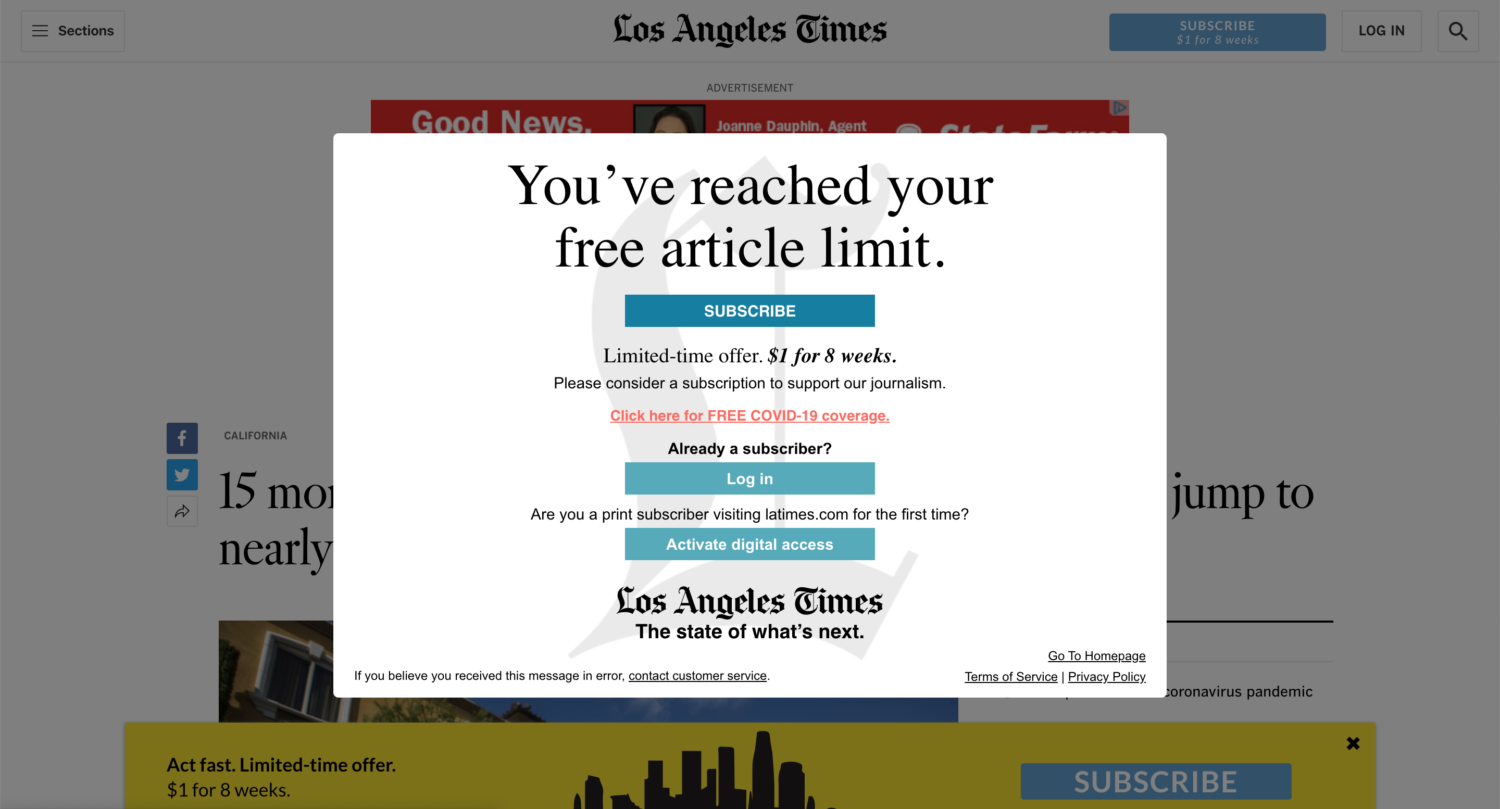
Misinformation
In addition to trying to profit off web scraping, some imposter domains may be used to deliver content that has been modified in a way to intentionally spread misinformation, harm reputations, or for political or other purposes.
Managing The Results
Now that you have a way to identify and track when imposter domains are re-publishing your website, what are the next steps? Tools are only as valuable as our ability to use them effectively, so it is important to develop a strategy for using an imposter domain tracking solution as part of your business processes. At a high level, I think this reduces to making decisions about a three-step management process:
1. Identifying Threats Through Regular Reporting
Once you have developed the database queries to extract potential imposter domain data from your web analytics or Real User Measurement data, you need to look at the data on a regular basis.
As a starting point, I would recommend a weekly report that can be quickly scanned for any new activity. A weekly report seems like the best cadence for catching problems before they become too severe. A daily report might feel tedious and become something easy to ignore after a while. Daily numbers can also be more challenging to interpret, as you can be looking at quite small numbers of page views that may or may not represent a concerning trend.
On the other hand, monthly reporting can result in problems going on for too long before being caught. A weekly report seems like the right balance for most sites and is probably the best starting cadence for regular reporting.
2. Categorization Of The Potential Threat
As we considered above, not all imposter domains re-publishing your site content are necessarily malicious in nature or a concern to your business. As you gain experience with the landscape of your own site’s data, you might enhance your regular reporting by color-coding or separating domains that you know about and consider non-malicious to help you focus on the unknown, new, or known problem domains that matter the most.
Depending on your needs, you might build up arrays of “acceptable” and “problem” domains, or categorize the imposter domains by their function or type (such as the “natural language translation” or “content publishing tools” categories described above). Every site will have different needs, but the objective is to separate the problematic domains from the domains that are not concerning.
3. Take Action Against The Bad Actors
For each of the problematic categories you identify, determine the parameters you want to use when deciding how to respond to the threat:
- What is the minimum page view count before we take action?
- What is the first point of escalation and who is responsible for it?
- Which stakeholders inside the business need to be aware of the malicious activity and when?
- Are the actions to be taken documented and reviewed by all stakeholders (executives, legal, etc.) on a regular basis?
- When actions are taken (such as filing a “DMCA Takedown” notice with the offender or their service provider or updating Web Application Firewall rules to try to limit access to the content thieves) are the results of these actions tracked and acknowledged?
- How will the effectiveness of these actions be summarized to executive business leaders over time?
Even if you are unsuccessful in squashing every malicious republication of your site content, you should still build a solid process in place to manage the risks like any other risk to the business. It will generate trust and authority with your business partners, investors, employees, and contributors.
Conclusion
In the right circumstances, your web analytics or real user measurement data can offer visibility into the world of imposter domains, used by web scrapers to re-publish your site content on their servers. Many of these imposter domains are actually benign services that either help end-users or help you in various productive ways.
In other cases, the imposter domains have malicious motives, either to steal content for profit or to manipulate it in a way that causes harm to your business or your site visitor. Web analytics or RUM data is your secret weapon to help identify any potentially malicious imposter domains that require immediate action, as well as to better understand the prevalence of the more benign domains. The data you collect leverages the web analytics or RUM service’s position as an observer in the visitor’s own browser to see that which your platform monitoring and reporting tools cannot.
Analyzing the data over time, you can learn more and more about imposter domains and their intentions in order to better inform your business about the risks they are posing to your reputations and your visitors’ experiences and develop and enforce mechanisms to protect your intellectual property.
Further Reading
- Protecting Your Site With Feature Policy
- Make Your Sites Fast, Accessible And Secure With Help From Google
- What You Need To Know About OAuth2 And Logging In With Facebook
- Content Security Policy, Your Future Best Friend
- Pushing Back Against Privacy Infringement On The Web


